Trino On Yarn: Maximizing Resource Utilization
Containerization
Containerization of software applications is a well known concept in the software world, Everyone knows the flexibility and isolation provided by containerizing an application. In Data world, There are many orchestration tools available today Kubernetes, Mesos & YARN are the mostly adopted ones.
Today, our focus will be on YARN containers. Apache Hadoop YARN was originally developed to execute isolated Hadoop data-intensive Java processes. In version 3.0, Docker support was added. YARN is a centralized resource manager that utilizes a capacity queues model to segregate resources among different tenets. Each tenet or team is assigned a certain percentage quota of the cluster with a predefined priority, ensuring resource availability for everyone. Hadoop is widely used in organizations for on-premises clusters, and there are numerous SQL engines that have native Hadoop support. Compared to Kubernetes, YARN has a simpler architecture with a straightforward learning curve. However, as the storage and processing separation model has made a comeback in the industry, many organizations are migrating from Hadoop to Kubernetes for heavy data processing due to its flexibility and native cloud support.
YARN Service API
The YARN Service API provides a way to manage and deploy long-running services on a Hadoop cluster.It is designed to make it easier to run and manage services that need to be highly available, scalable, and fault-tolerant stateful or stateless services. its design provides a declarative way to define services using a YAML-based specification file that includes information such as the service name, number of instances and the dependencies. it provides a way to manage the lifecycle of the services, including starting, stopping, scaling, automatic failover, rolling upgrades, and integration with Hadoop's security and monitoring systems
Service Definition : A YAML-based specification file that describes the service and its properties, including the service name, the number of instances, the resource requirements, dependencies, and other details.
Service Instance : A running instance of a service, which is created based on the service definition. A service can have multiple instances, which can be scaled up or down based on demand.
Component : A component is a single process or container that runs as part of a service instance. A service can have multiple components, each with its own resource requirements.
Resource Profile : A set of resource requirements for a service instance or component, including CPU, memory, and disk space. Resource profiles are used to allocate resources and ensure that a service instance or component has the necessary resources to run.
Placement Constraints : Rules that define where a service instance or component can be placed within a cluster. Placement constraints can be used to ensure that services are distributed across nodes in a balanced way.
Service Lifecycle : The lifecycle of a service, including starting, stopping, upgrading, and scaling. The Service API provides methods for managing the service lifecycle, including APIs for creating, updating, and deleting services, and for scaling service instances up or down.
Trino
Trino is a distributed SQL query engine designed to query large data sets distributed over one or more heterogeneous data sources. It is based on the JVM model and can run bare metal or use any common resource manager such as K8S or YARN. Trino Does not have native support for Yarn Resource Manager and also, YARN service API is still in GA mode as of Hadoop3.3; This article is for knowledge purposes only. Please take due diligence before implementing this solution in production.
Trino is a very lightweight java SQL engine based on the Controller & Worker architecture same as Presto.
Coordinator
The Coordinators server works as the controller for the whole Trino cluster it accepts a user query, parse and analyzes the sql syntax, Create an execution plan and schedule it on the workers for execution. Coordinator in itself is a very light process, and in production systems, it is not recommended for any heavy lifting of data processing. All end users connect to the coordinator for the query execution.
Discovery URI
The coordinator process also contains another endpoint which is used by all the worker nodes to share a heartbeat every x seconds across the cluster. It helps the coordinator process to make intelligent scheduling decisions during the execution of a user request. The coordinator will not schedule a query on a node where the last heartbeat is older than a defined threshold. The Discovery server also publishes the total cluster worker status to all the nodes, which help in fault toleration in case of a worker process dies.
Worker
The worker process performs dumb query execution job as defined and scheduled by the coordinator on the cluster. The worker picks up a data split and processes it based on the pre-defined execution plan, and reports back the results to the coordinator.
YARN Service Demo
We will be launching the Trino service on YARN using the json file. the flow will be as below.
Coordinator Deployment:
-
A Coordinator & Discovery server endpoint outside the YARN cluster so we can have a dedicated controller node to avoid any noisy neighbout scenario, we can add the coordinator service on YARN containers as well but it will be impacted by the running YARN services load and also as YARN does not provide and disc or network level seperation, We might end up impacting other running loads on YARN due to heavy Trino User QPS.
-
Download the artifacts for Trino and add the required condiguration files based on the instructions on this session here !
-
Assign a dedicated
node.id=ffffffff-ffff-ffff-ffff-ffffffffffffas we will not be changing this one in near future, It is better to use meaning ful value as it will show up in our Trino UI. -
We can assign
discovery.uri=localhost:8085as discovery end point will be running on same machine, Please make sure we have not changed the server port else use the new defined port in place of 8085. -
Launch the Coordinator using the launcher command and you can validate the deployment by going to
<coordinator_hst:8085>url. Trino UI should be up and there should be no worker nodes on the cluster at this point of time.
Worker Deployment (YARN)
Worker Deployment will be little complex as we need to create and Artifact of the worker node and ship it to the YARN service, We will be using the tarball artifact type for the demo. YARN also support docker type though we need to install docker executables on all the worker nodes.
-
Download the Trino Base Artifacts and set up the
etcconfiguration directory by following the instructiions given on the Trino deployment page. -
Create require
node.data.dir=/var/trino/dataon all the worker/data nodes on the cluster that have active node managers and where we are expecting to run our Trino workers. You can choose to create only on a specific set of nodes as well if you are planning to use YARN node Labels for Trino deployment. -
Once all files are created, generate a new tar file using
tar -cvzf trino-server-<version>.tar.gz <Trino Directory>, we will use this trino artifact to launch the Trino on YARN. -
Create a YARN App launcher file as below.
{
"name" : "trino-yarn-demo",
"version" : "1.0.0",
"artifact" : {
"id": "<hdfs_path_Artifact>/trino-server-412.tar.gz",
"type" : "TARBALL"
},
"resource" : {
"cpus" : 4,
"memory" : "12288"
},
"configuration" : {
"properties" : {
"yarn.service.container-failure-per-component.threshold": 1000,
"yarn.service.am-resource.memory": 3072
}
},
"lifetime" : -1,
"components" : [ {
"name" : "worker",
"dependencies" : [ ],
"readiness_check" : {
"type" : "HTTP",
"properties" : {
"url" : "http://localhost:8085/v1/info"
}
},
"launch_command" : "./conf/entrypoint.sh",
"resource" : {
"cpus" : 4,
"memory" : "12288",
"additional" : { }
},
"placement_policy": {
"constraints": [
{
"type": "ANTI_AFFINITY",
"scope": "NODE",
"target_tags": [
"worker"
]
}
]
},
"number_of_containers" : 10,
"run_privileged_container" : false,
"configuration" : {
"env" : {
"JAVA_HOME" : "/opt/java17/jdk-17.0.4.1",
"POTENTIAL_PATH" : "$JAVA_HOME/bin:$PATH",
"HADOOP_HOME" : "$PWD/lib/hadoop",
"HADOOP_YARN_HOME" : "$PWD/lib/hadoop",
"CONTAINER_CONFS" : "$PWD/conf",
"TRINO_ETC" : "$TRINO_HOME/etc",
"TRINO_ETC_CATALOG" : "$TRINO_ETC/catalog",
"TRINO_CONFIG_PROP_NAME_BEFORE" : "trino-config.properties",
"TRINO_CONFIG_PROP_NAME" : "config.properties",
"PORT": "8085"
},
"files" : [{
"type" : "PROPERTIES",
"dest_file" : "trino-node.properties",
"properties" : {
"node.environment": "poc",
"node.id": "${CONTAINER_ID}",
"node.data-dir": "/data/trino-yarn/data"
}
},{
"type" : "TEMPLATE",
"dest_file" : "entrypoint.sh",
"src_file" : "/user/hubble-poc/trino-confs-single-worker/entrypoint.sh",
"properties" : {}
}]
},
"restart_policy" : "ALWAYS"
}]
},
"queue" : <yarn-queue>,
"kerberos_principal" : { }
}
- We also need an
entrypoint.shfile in the directory where we are launching the yarn app in local.
#!/bin/bash
#Add variables for trino.
mkdir -p $TRINO_ETC_CATALOG
cp $CONTAINER_CONFS/trino-catalog-hive.properties $TRINO_ETC_CATALOG/hive.properties
cp $CONTAINER_CONFS/trino-catalog-iceberg.properties $TRINO_ETC_CATALOG/iceberg.properties
cp $CONTAINER_CONFS/trino-catalog-mysql.properties $TRINO_ETC_CATALOG/mysql.properties
cp $CONTAINER_CONFS/trino-jvm.config $TRINO_ETC/jvm.config
cp $CONTAINER_CONFS/trino-node.properties $TRINO_ETC/node.properties
cp $CONTAINER_CONFS/trino-config.properties $TRINO_ETC/config.properties
cp $CONTAINER_CONFS/resource-groups.properties $TRINO_ETC/resource-groups.properties
#Set path to Java17+ manually as Trino need Java 17+ and hadoop runs on Java 8,
#we need to manually push the java17 to all worker nodes to a specific directory
#and set path at the time of launching trino.
export PATH=$JAVA_HOME/bin:$PATH
java -version
echo "Check Java Version..."
#cat $PWD/conf/trino-node.properties
#cat $PWD/conf/trino-node-test2.properties
## Launch Trino in the YARN Container.
$PWD/lib/trino-server-415/bin/launcher run
- SSH into your yarn client machine and Once all the files are created launch the yarn app with comand
yarn app -launch <app-name> yarn-trino-demo.json, Make sure you have both above files in the same direcotry where you are launching the app.
Trino UI
- Open the Coordinator server on port 8085 you will see the UI with active worker count as per out requirement of 10 contaners in the launch file.
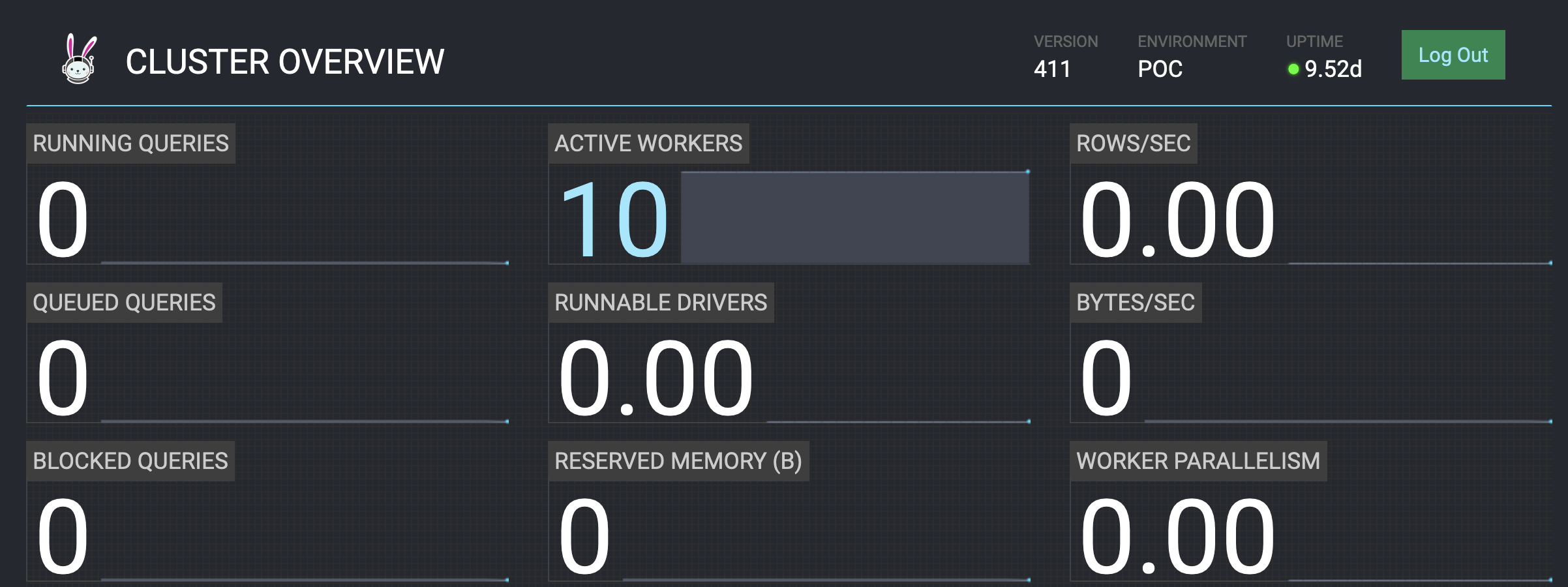
YARN Service API is still in GA mode and it is getting better with the new releases, Running Trino on K8s is another good idea how ever with Hadoop we will be sending the user queries to the data and it is very useful when you are scanning peta bytes of data every day as Data localcity help to minimize the data shuffling across the network.
Please feel free to try it out and let me know if any questions. Thanks for reading.